Data Challenge IDEMIA-MS Big Data
MS Telecom Big Data
Challenge Large Scale Machine Learning
Fusion of algorithms for face recognition
- Yang WANG
The increasingly ubiquitous presence of biometric solutions and face recognition in particular in everyday life requires their adaptation for practical scenario. In the presence of several possible solutions, and if global decisions are to be made, each such single solution can be far less efficient than tailoring them to the complexity of an image.
In this challenge, the goal is to build a fusion of algorithms in order to construct the best suited solution for comparison of a pair of images. This fusion will be driven by qualities computed on each image.
Comparing of two images is done in two steps. 1st, a vector of features is computed for each image. 2nd, a simple function produces a vector of scores for a pair of images. The goal is to create a function that will compare a pair of images based on the information mentioned above, and decide whether two images belong to the same person.
There are in total 9,800,713 training observations. There are in total 3,768,311 test observations.
The performance criterion
You need to manage the trade-off between the true positive rate (TPR) and the false positive rate (FPR), depending on the cost of the corresponding mistakes.
Here, the performance criterion is TPR for the value of FPR = 0.0001, or, speaking in other words, one needs to maximize the value of the receiver operating characteristic (ROC) in the point FPR = 0.0001.
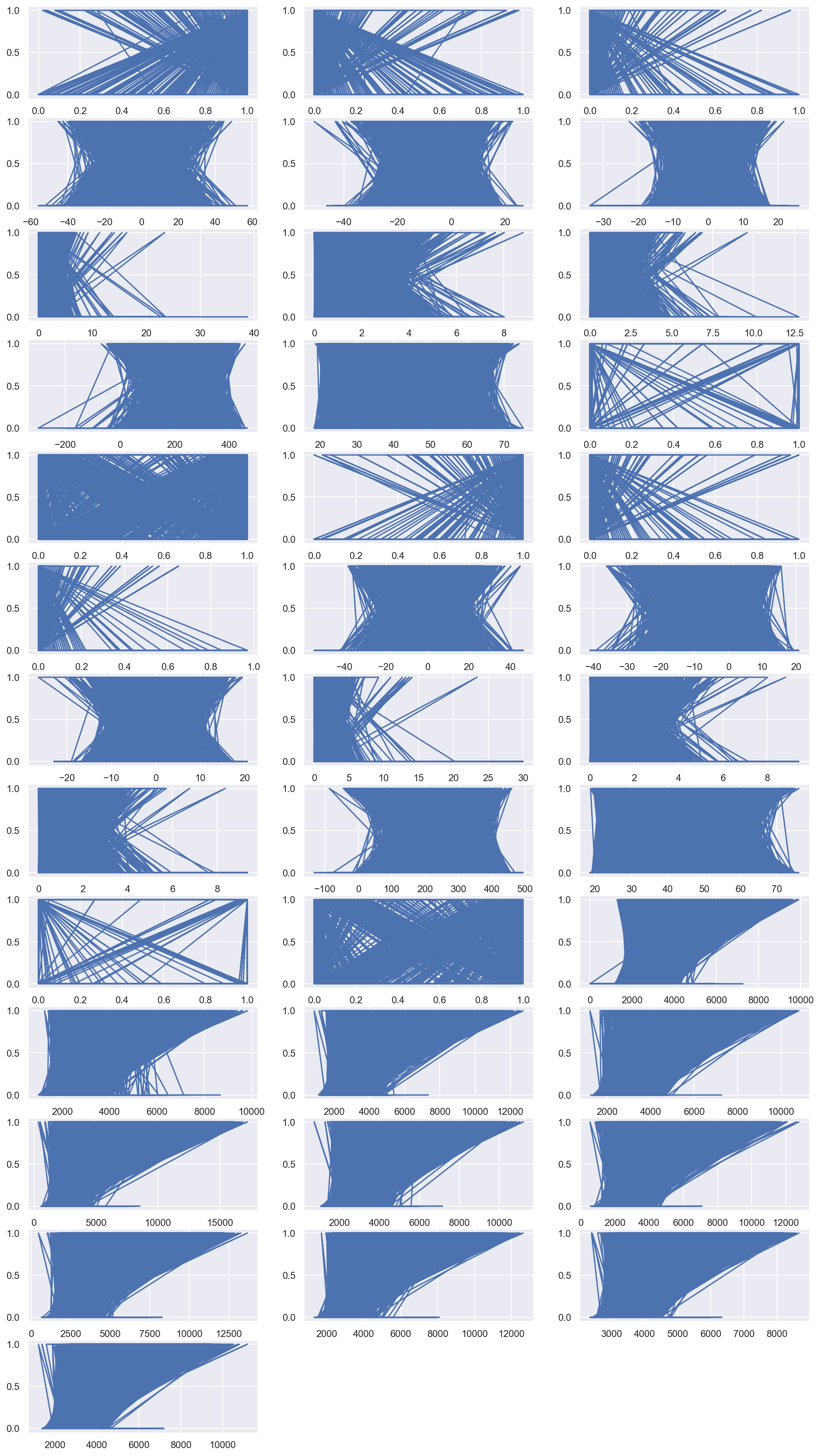
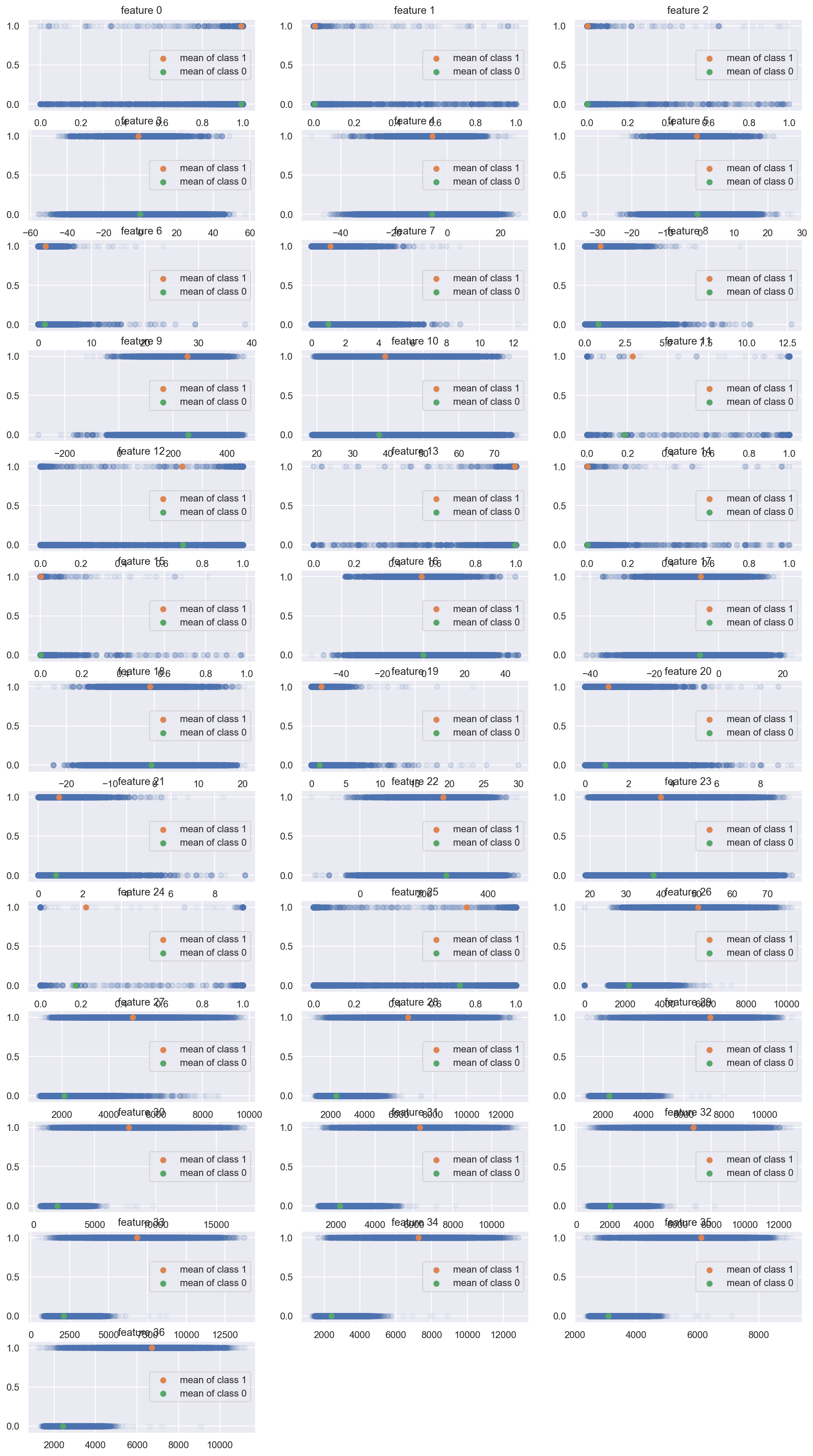
EDA
I invented some graphs to see the correlations amonge features.
Main algorithm used - (Customized) Lightgbm
Custom Loss Function, penalty for FP
In many cases, we cann’t assume that the cost of classifying things is equal. For example, we build a system to detect whether a horse with stomach pain would end up living or dying. Let’s say someone brings a horse to us and asks us to predict whether the horse will live or die. We say die, and rather than delay the inevitable, making the animal suffer and incurring veterinary bills, they have it euthanized. Perhaps our prediction was wrong, and the horse would have lived. If we predicted this incorrectly, then an expensive animal would have been destroyed, not to mention that a human was emotionally attached to the animal.
Besides tuning the thresholds of our classifier, there are other approaches e to aid with uneven classification costs. One such method is known as costsensitive learning.
Xgboost use a second ordre Taylor approximation,light gbm also request the gradient and the hessien in its cost function, very alike to Xgboost. For binary classification, we use a log loss: 𝐿=−𝑦ln𝑝−𝛽(1−𝑦)ln(1−𝑝)$$ $p$ as the probability estimated by sigmoid function. 𝛽 is the multiplier factor to increase the weight of FP loss.
In order to penalise False Positive, I put a penalty Beta on the FP, I can calculate the gradient as:
grad =∂𝐿/∂𝑥=∂𝐿/∂𝑝*∂𝑝/∂𝑥=𝑝(𝛽+𝑦−𝛽𝑦)−𝑦 ,
and hessien as:
hess =∂2/𝐿∂𝑥2=𝑝(1−𝑝)(𝛽+𝑦−𝛽𝑦)
Customizing the training loss in LightGBM requires defining a function that takes in two arrays, the targets and their predictions. In turn, the function should return two arrays of the gradient and hessian of each observation. As noted above, we need to use calculus to derive gradient and hessian and then implement it in Python.
Custom Eval Metric TPR
Validation loss: This is the function that we use to evaluate the performance of our trained model on unseen data. This is often not the same as the training loss. For example, in the case of a classifier, this is often the area under the curve of the receiver operating characteristic (ROC) — though this is never directly optimized, because it is not differentiable. This is often called the “performance or evaluation metric”. The validation loss is often used to tune hyper-parameters.
Because it doesn’t have as many functional requirements like the training loss does, the validation loss can be non-convex, non-differentiable, and discontinuous, we can use our Specific True Positive Rate (conditionned by FP < 10e-4) as validation loss. The validation loss in LightGBM is called metric.